
Comparative Agility questions are scored on a 5-point Likert scale, where answers such as “True” are worth 5 points, “More True than False” are 4 points, and so on. (Not Applicable is not counted.) When you look at the report, you have three different perspectives on the data available to you.
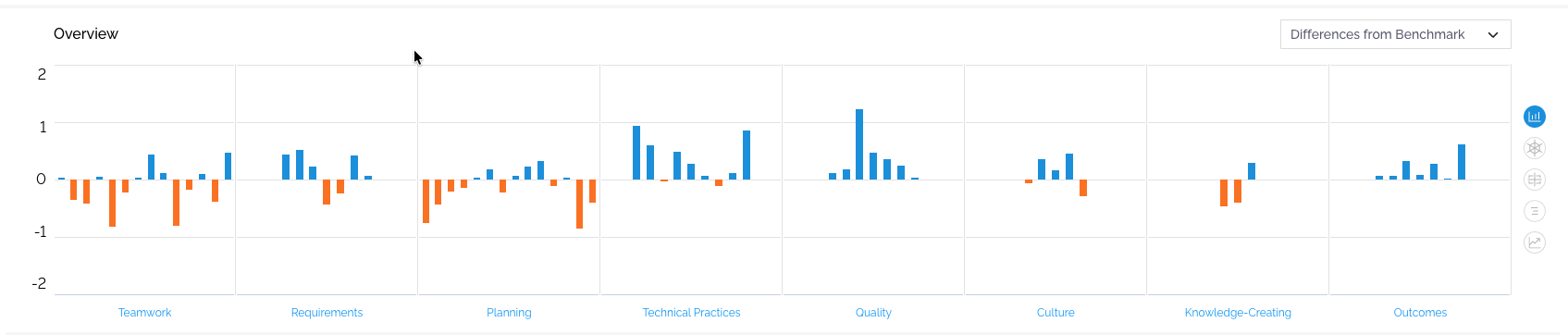
Differences from Benchmark
In this case, what we are doing is looking at the differences in the averages of the dataset you choose in the “Analysis” screen (left side) from the benchmark dataset you choose on the right side of the screen. So if – for instance – your average score of the dataset you chose on the left side was 4.3 and the average score for the same data item was 3.9, what will be displayed is the difference between the two: in this case 4.3- 3.0 = 1.3, a positive score which indicates that compared to the benchmark (whatever you chose on the right side of the Analysis screen), your dataset compared favorably by 1.3. So what does 1.3 mean? Well, it essentially means that your dataset indicates that they feel that the given question is more true for them than it is for the benchmark dataset. Let’s assume the question was “Our team delivers more value to the customer than before.” Then, what the data indicates is that this is a statement that the team indicates is indeed more correct now compared to the benchmark. The scale, then, in this case, indicates the differences between the two datasets. (And this is why you’ll have negative scores – if your dataset compares unfavorably to the benchmark.)
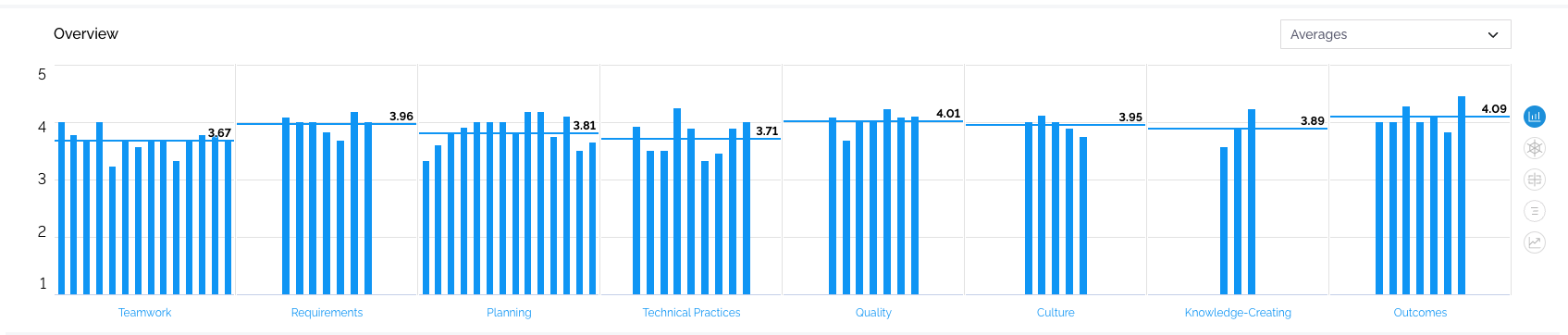
Averages
In this case, we are looking at the raw average score for the dataset you picked to the left on the Analysis screen. The scale is pretty straightforward; the highest possible score is 5, which is equivalent to “True”.
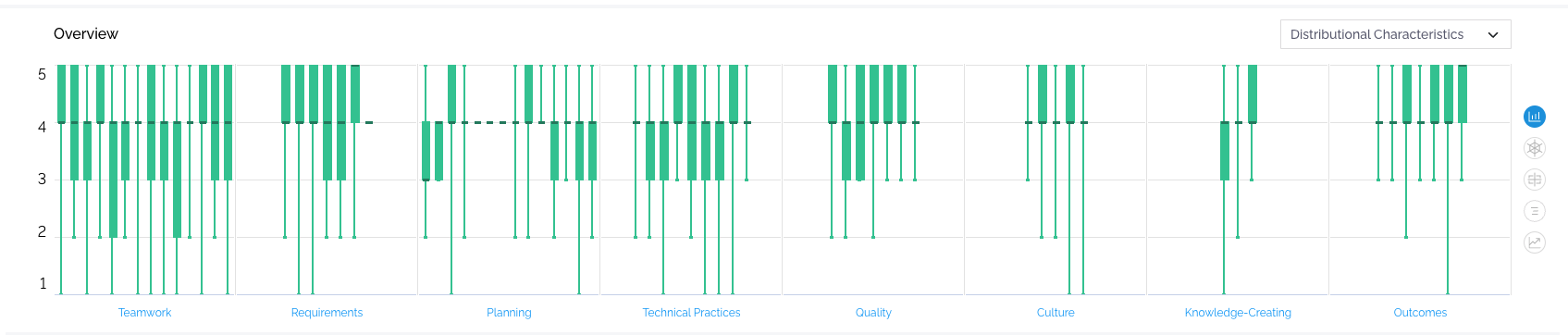
Distributional Characteristics
In this case, we are looking at the variance of the dataset you chose on the left-hand side. In other words, we are looking at the level of coherence or agreement within your dataset. We are using something called Boxplots, which indicate where the majority of the data resides. So if you have 10 data points in your dataset and the majority of the data falls between 2 and 4, you’ll have a vertical bar that stretches from 2-4. Now, you may still have some outliers – some extreme values – and they will be indicated by the long lines attached to the box plots. So, using the same example, if the majority of the data is within 2 and 4, but some people answered maybe a 1 or a 5 (which means they have very different opinions), this will be indicated in this chart. The scale on the X-axis is the same – 5 indicates “True”, 4 indicates “More True than False”, and so forth.
If you have any questions or need assistance, don’t hesitate to reach out to our support team at support@comparativeagility.com and we will be more than happy to help you.